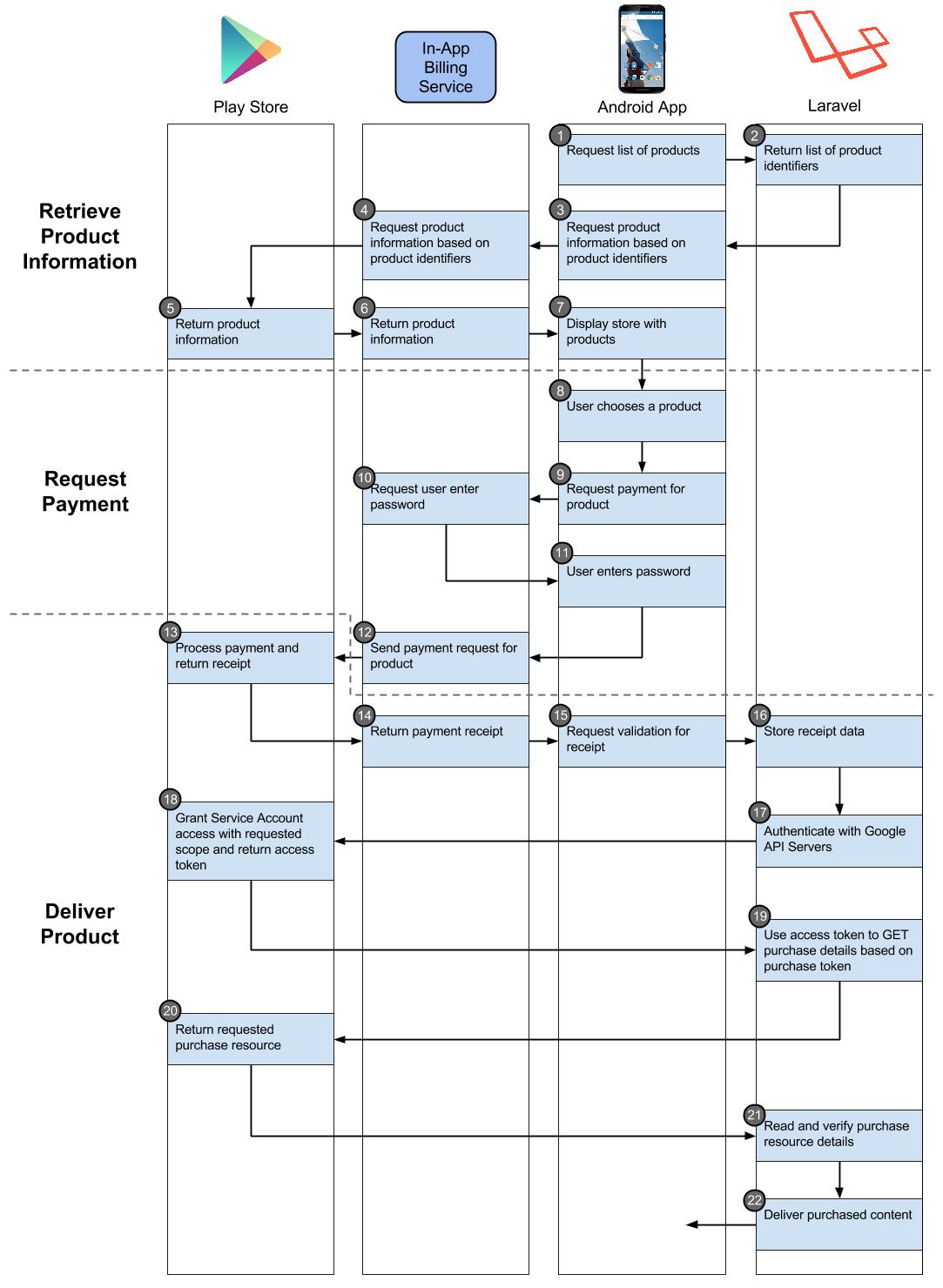
Hot on the heels of my Laravel on AWS Elastic Beanstalk Dev Guide (i.e., 2.5 years later), I’m happy to publish my Laravel 5 on AWS Elastic Beanstalk Production Guide! So let’s dive right into it.
Background
There have been a lot of changes with Laravel and with Elastic Beanstalk since my Dev Guide in 2014. This guide steps you through the process of deploying a Laravel 5 app to AWS Elastic Beanstalk.
I presented this deployment flow during the February LaravelSF Meetup event at the AWS Loft in San Francisco. During my presentation I used my demo app, LaraSqrrl, to show the process, along with integration with S3 and SQS (upcoming posts).
Prerequisites
As in my previous guide, there are some prerequisites before you jump into the guide:
- You should have an AWS account.
- You have git installed and a git repo initiated for your project.
- You should familiarize yourself with Elastic Beanstalk.
RDS Database
I like to keep my RDS instance separated from Elastic Beanstalk, as RDS instances created by and associated with an Elastic Beanstalk environment will be terminated when the environment is terminated. Separating the RDS instance from the environment allows you to keep the same database regardless of the environment.
Step 1: Choose your engine
Choose whichever database engine your app is set up for. I generally use MySQL with Laravel, so that’s what I’ll select.